Computer Vision
Global Feature & Local Feature
Regression
Regression tree
Differentiation
Partial differentiation
Gradient
Gradient descent
Gradient boosting
Adaptive boosting
Shape indexed feature
Local binary pattern
Global features (e.g., color and texture) aim to describe an image as a whole and can be interpreted as a particular property of the image involving all pixels.
While, local features aim to detect keypoints or interest regions in an image and describe them. In this context, if the local feature algorithm detects n keypoints in the image, there aren vectors describing each one’s shape, color, orientation, texture and more.
The use of global colour and texture features are proven surprisingly successful for finding similar images in a database, while the local structure oriented features are considered adequate for object classification or finding other occurrences of the same object or scene.
Meanwhile, the global features can not distinguish foreground from background of an image, and mix information from both parts together.
While, local features aim to detect keypoints or interest regions in an image and describe them. In this context, if the local feature algorithm detects n keypoints in the image, there aren vectors describing each one’s shape, color, orientation, texture and more.
The use of global colour and texture features are proven surprisingly successful for finding similar images in a database, while the local structure oriented features are considered adequate for object classification or finding other occurrences of the same object or scene.
Meanwhile, the global features can not distinguish foreground from background of an image, and mix information from both parts together.
Additionally, local feature descriptors are proven to be a good choice for image matching tasks on a mobile platform, where occlusions and missing objects can be handled.
Global features can be interpreted as a particular property of image involving all pixels. This property can be color histograms, texture, edges or even a specific descriptor extracted from some filters applied to the image. On the other hand, the main goal of local feature repre- sentation is to distinctively represent the image based on some salient regions while remaining invariant to viewpoint and illumination changes. Thus, the image is rep- resented based on its local structures by a set of local feature descriptors extracted from a set of image regions called interest regions
Feature detectors can be classified into three categories:
single-scale detectors, multi-scale detectors, and affine invariant detectors.

Affine Invariant Detectors
SIFT(Scale-Invariant Feature Transform)
There are mainly four steps involved in SIFT algorithm.
Build Scale Space
Four Octave of Images are generated. 1st octave is in original scale, lowering scale in every octave. Every Octave has 5 images with lowering the gaussian sigma. acts as a scaling parameter. Gaussian kernel with low gives high value for small corner while guassian kernel with high fits well for larger corner. Int default, number of octaves = 4, number of scale levels = 5, initial
acts as a scaling parameter. Gaussian kernel with low gives high value for small corner while guassian kernel with high fits well for larger corner. Int default, number of octaves = 4, number of scale levels = 5, initial  ,
,  .
.
LoG acts as a blob detector which detects blobs in various sizes due to change in.But this LoG is a little costly, so SIFT algorithm uses Difference of Gaussians which is an approximation of LoG. Difference of Gaussian is obtained as the difference of Gaussian blurring of an image with two different .
A discrete maximum in our case is a pixel whose gray value is larger than those of all of its 26 neighbor pixels. Here we count as "neighbors" the eight adjacent pixels in the same picture, the corresponding two pixels in the adjacent pictures in the same octave, and finally their neighbors in the same picture.
Detect Extrema
Assign Orientations
Extract Keypoint Descriptors
http://crcv.ucf.edu/people/faculty/shah.php
https://www.youtube.com/watch?v=NPcMS49V5hg
https://github.com/aishack/sift/blob/master/SIFT.cpp
http://weitz.de/sift/
https://www.cse.iitb.ac.in/~ajitvr/CS763/SIFT.pdf
https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_feature2d/py_sift_intro/py_sift_intro.html
SURF
https://dsp.stackexchange.com/questions/13577/understanding-surf-features-calculation-process
https://github.com/xieguotian/SurfFaceDetection
https://github.com/abhinavgupta/SURF
https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_feature2d/py_surf_intro/py_surf_intro.html
LBP
single-scale detectors, multi-scale detectors, and affine invariant detectors.
Single-Scale Detectors
Harris Detector
SUSAN Detector
FAST Detector (Features from Accelerated Segment Test)
Entropy
Entropy is just a way of expressing the number of states of a system. A system with many states has a high entropy, and a system with few states has a low entropy. The higher the entropy (meaning the more ways the system can be arranged), the more the system is disordered.
Feature Detection
Entropy
Entropy is just a way of expressing the number of states of a system. A system with many states has a high entropy, and a system with few states has a low entropy. The higher the entropy (meaning the more ways the system can be arranged), the more the system is disordered.
Feature Detection
- Select a pixel P in the image and select a radius 3 to check the pixels along the circular path of this radius.

- Now the pixel
 is a corner if there exists a set of
is a corner if there exists a set of 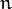 contiguous pixels in the circle (of 16 pixels) which are all brighter than
contiguous pixels in the circle (of 16 pixels) which are all brighter than  , or all darker than
, or all darker than  . = 12.
. = 12. - A high-speed test was proposed to exclude a large number of non-corners. This test examines only the four pixels at 1, 9, 5 and 13. If is a corner, then at least three of these must all be brighter than or darker than . Then all a6 pixels need to be checked for the pixel being corner. This detector in itself exhibits high performance, but there are several weaknesses:
- It does not reject as many candidates for n < 12.
- The choice of pixels is not optimal because its efficiency depends on ordering of the questions and distribution of corner appearances.
- High speed test will not work for n<12.
- Multiple features are detected adjacent to one another.
First 3 points are addressed with a machine learning approach. Last one is addressed using non-maximal suppression.
Machine Learning a Corner Detector
- Select a set of images for training (preferably from the target application domain)
- Run FAST algorithm in every images to find feature points.
- For every feature point, store the 16 pixels around it as a vector. Do it for all the images to get feature vector
 .
. - Each pixel (say
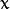 ) in these 16 pixels can have one of the following three states:
) in these 16 pixels can have one of the following three states:
- Every pixel has 16 value for surrounding 16(bbbbbbbbbbbbbbbb) pixels as d/s/b as the above equation and count of this duplicate vector with corner/non_corner.
- These vectors will be split into three subsets,
 ,
,  ,
,  . by choosing a split index from those 16 pixels.Which is done by calculating the entropy for every indices of the 16 pixels for all vectors and choose the index where lowest enrtopy occurs.
. by choosing a split index from those 16 pixels.Which is done by calculating the entropy for every indices of the 16 pixels for all vectors and choose the index where lowest enrtopy occurs.
- And recursively subdivided the tree node in subsequent three node as above until there is only one leaf.
- The leaf will have the corner info if this is corner or not. After building this tree, this will use to identify corners in any image required.
Non-maximal Suppression
This procedure is done after the feature detection process with above machine learned (ID3) classifier tree.
Detecting multiple interest points in adjacent locations is another problem. It is solved by using Non-maximum Suppression.
- Compute a score function,
 for all the detected feature points. is the sum of absolute difference between and 16 surrounding pixels values.
for all the detected feature points. is the sum of absolute difference between and 16 surrounding pixels values. - Consider two adjacent keypoints and compute their values.
- Discard the one with lower value.
FAST corner detector is very suitable for real-time video processing applications because of its high-speed performance. However, it is not invariant to scale changes and not robust to noise, as well as it depends on a threshold.
Multi-scale Detectors
Laplacian of Gaussian (LoG)
Difference of Gaussian (DoG)
Affine Invariant Detectors
SIFT(Scale-Invariant Feature Transform)
There are mainly four steps involved in SIFT algorithm.
Build Scale Space
Four Octave of Images are generated. 1st octave is in original scale, lowering scale in every octave. Every Octave has 5 images with lowering the gaussian sigma.
acts as a scaling parameter. Gaussian kernel with low gives high value for small corner while guassian kernel with high fits well for larger corner. Int default, number of octaves = 4, number of scale levels = 5, initial , .LoG acts as a blob detector which detects blobs in various sizes due to change in
.But this LoG is a little costly, so SIFT algorithm uses Difference of Gaussians which is an approximation of LoG. Difference of Gaussian is obtained as the difference of Gaussian blurring of an image with two different .A discrete maximum in our case is a pixel whose gray value is larger than those of all of its 26 neighbor pixels. Here we count as "neighbors" the eight adjacent pixels in the same picture, the corresponding two pixels in the adjacent pictures in the same octave, and finally their neighbors in the same picture.
Detect Extrema
Assign Orientations
Extract Keypoint Descriptors
http://crcv.ucf.edu/people/faculty/shah.php
https://www.youtube.com/watch?v=NPcMS49V5hg
https://github.com/aishack/sift/blob/master/SIFT.cpp
http://weitz.de/sift/
https://www.cse.iitb.ac.in/~ajitvr/CS763/SIFT.pdf
https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_feature2d/py_sift_intro/py_sift_intro.html
SURF
https://dsp.stackexchange.com/questions/13577/understanding-surf-features-calculation-process
https://github.com/xieguotian/SurfFaceDetection
https://github.com/abhinavgupta/SURF
https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_feature2d/py_surf_intro/py_surf_intro.html
LBP
Regression
Regression tree
Differentiation
Partial differentiation
Gradient
Gradient descent
Gradient boosting
Adaptive boosting
Shape indexed feature
Local binary pattern

Comments
Post a Comment